Research
Model Fusion Without Training Data: Graph-Aligned Weight Merging
In neuroscience, machine learning models are often trained in a task- and subject-specific manner, driven by limited data and substantial variability across individuals. A familiar example is brain–computer interfaces (BCIs), where models that decode motor intentions from EEG are typically trained separately for each user. While these personalized networks can perform well within their original setting, they often fail to generalize across users, sessions, or tasks. Joint training across subjects or tasks is a natural alternative and can improve generalization, but it is frequently impractical: multi-task models are harder to optimize, raw data access is often restricted by privacy and ethical constraints, and the continued growth of large datasets makes centralized training increasingly expensive.
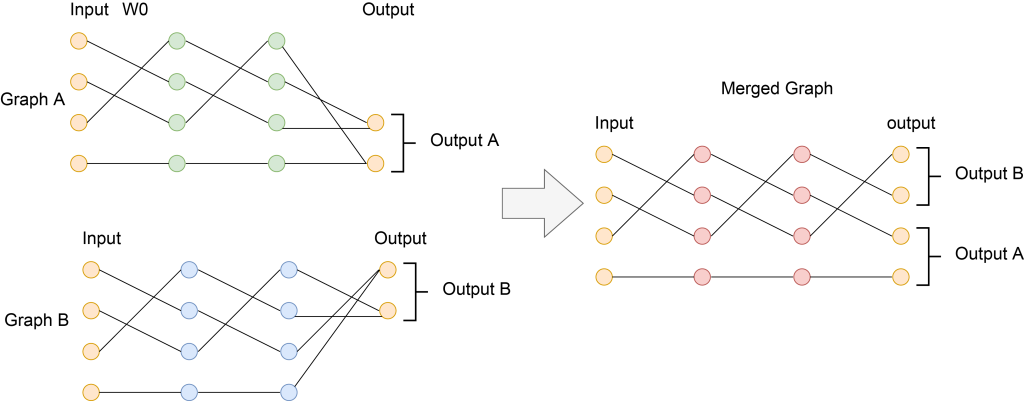
To address these challenges, we are developing a framework for merging independently trained neural networks into a single multi-task model without access to the original training data. The approach assumes a shared architecture across models but allows each network to be optimized for a different task (or subject). We represent each trained model as a compact weight graph defined by its linear layers, then align and merge these graphs via an optimization procedure that preserves structural consistency and information flow from each network. The merged graph is subsequently translated back into a new set of network weights.
This strategy enables the fusion of specialized models into a unified network that supports multi-task functionality while preserving task-specific performance. By combining representational pathways learned independently—without sharing raw data—our approach offers a scalable route to leveraging existing models and moving beyond the limitations of centralized multi-task training.